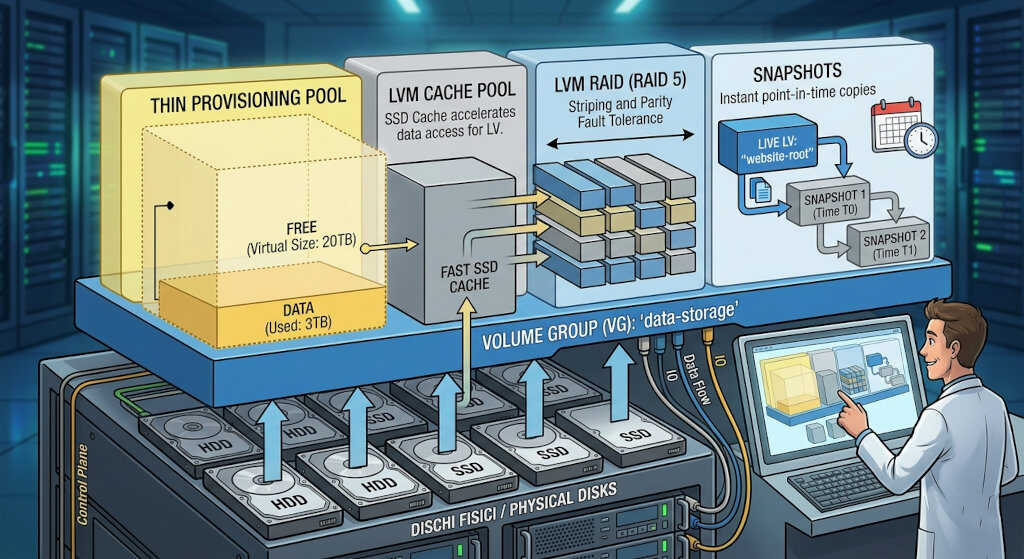
 Oltre che alla grande flessibilità nella gestione dei volumi, LVM attraverso device mapper, aggiunge tutta una serie di ulteriori capacità che rendono questa tecnologia estremamente versatile.
Oltre che alla grande flessibilità nella gestione dei volumi, LVM attraverso device mapper, aggiunge tutta una serie di ulteriori capacità che rendono questa tecnologia estremamente versatile.
La possibilità di disporre di meccanismi per la gestione di snapshot, cache pool. thin provisioning e raid, rendono LVM qualcosa di più di un gestore di volumi.
1. Snapshot
Le snapshot LVM usano la tecnica del Copy-on-Write (CoW) allo scopo di ridurre la duplicazione.
La snapshot dovrà essre la fotografia del volume prima all'origine.
Ad ogni modifica / cancellazione, il file originale verrà portato sulla snapshot prima dell'operazione.
Sul volume originale verranno scritti tutti i dati nuovi e quelli modificati.
Per il ripristino, si effettua quello che si chiama merge, dove i dati vecchi vengono ripristinati dalla snapshot e quelli nuovi cancellati dal volume.
Per il consolidamento delle modifiche, basterò rimuovere la snapshot,
1.1. Attenzione: Dimensione della snapshot
Se la snapshot ha la stessa dimensione del volume logico non ci sono problemi.
Se è più piccola, occorre prestare attenzione a che la quantità dei dati modificati sul volume logico non superino la dimensione della snapshot.
In questo caso infatti la snapshot risulterà inutilizzabile e non potrà più essere usata per il ripristino ma potrà essree solo rimossa.
1.2. Esempio
Supponiamo di avere un gruppo di volumi, my_vg, composto da 3 volumi logici:
- lv_root (30 GiB)
- lv_home (200 GiB)
- lv_dati (500 GiB)
e di voler creare una snapshot precauzionale sulla root (supponendo di avere spazio a sufficienza altrimenti dovrò fare bene i miei conti per non riempire oltremisura la snapshot rendendola inservibile).
Creazione snapshot
lvcreate -s -L 30G -n lv_root_snap my_vg/snap
Ripristino
umount /dev/my_vg/lv_root
lvconvert --merge my_vg/snap
Consolidamento
lvremove snap
2. Thin Pool
Il thin provisioning di LVM è l'alternativa dinamica alla classica gestione di volumi, thick, che prevede l'assegnazione statica delle dimensioni dei volumi.
Se è vero che il thick provisioning risulta comunque abbastastanza agevole per via della flessibilità intrinseca dei volumi in caso di riduzione o aumento della superficie allocabile, il thin provisioning può aumentare i vantaggi derivanti da LVM in alcuni scenari.
Il thin provisioning si basa sul principio che lo spazio assegnato ai volumi non viene usato mai completamente e mai tutto in una volta.
Ecco perché un'allocazione dinamica ci permetterebbe di definire volumi che si riempiono solo man mano che lo spazio viene occupato.
Se si opta per un thin provisioning sarebbe opportuno non usare tutto il gruppo di volumi ma lasciarne un 20% in previsione di future espansioni.
Con i thin pool non solo abbiamo la stessa flessibilità della gestione thick, ma possiamo lavorare anche in over provisioning ossia creare pool di volumi la cui somma potenziale sia superiore allo spazio realmente allocabile.
Es. Supponiamo avere un device da 100 GiB, /dev/sdb, su cui definisco un volume group e creare un thin pool di 50 GiB. Su questo thin pool creeremo 3 volumi “virtuali” da 20, 30 e 20 GiB.
# creazione volume group di 100 GiB
vgcreate vg_lab /dev/sdb
# creazione thin pool da 50 GiB
lvcreate -L 50G --thinpool vg_lab/lv_tp
# creazione dei 3 volumi virtuali in "over provisioning"
lvcreate -V 20G --thin -n vol1_virt --thinpool vg_lab/lv_tp
lvcreate -V 30G --thin -n vol2_virt --thinpool vg_lab/lv_tp
lvcreate -V 20G --thin -n vol3_virt --thinpool vg_lab/lv_tp
Una volta creati i volumi possono essere formattati e montati come di consueto.
Lo spazio effettivamente occupato è quasi nullo, il sistema solleverà solo un warning per avvertirci che i volumi virtuali rischiano di saturare lo spazio disponibile.
Ecco perché bisogna prestare attenzione al raggiungimento della soglia critica.
Bisognerà estendere subito il thin pool ed i volumi virtuali nel modo consueto.
⚠️⚠️⚠️ ATTENZIONE ⚠️⚠️⚠️
L'estensione di un volume virtuale non differisce molto da quello di un volume “classico”.
Se lo spazio per le fette si sta esaurendo, si estendono nell'ordine:
- il gruppo di volumi (se necessario)
- il thin pool (se nel volume group c'è spazio a sufficienza)
- i volumi virtuali
- i filesystem
Se non siamo con l'acqua alla gola, i punti 3 e 4 sono sufficienti. L'estensione del volume virtuale è più rapida di quella classica perché non viene allocato spazio.
L'estensione di un volume logico classico corrisponde all'estensione del thin pool.
Nel caso di riduzione, la situazione cambia parecchio perché la riduzione di un volume virtuale non fa guadagnare spazio allocabile visto che l'ampiezza del volume è solo teorica, ciò avviene solo con fstrim.
Inoltre accorciando il volume virtuale al di sotto dei dati effettivamente scritti, si rischia di corrompere l'intero filesystem.
Consiglio spassionato: ESTENDI SEMPRE E NON RIDURRE MAI!!!
Altra considerazione va fatta anche per i metadati.
A differenza dell'LVM classico dove la creazione di un volume logico necessitava di un extent per i metadati, il thin provisioning di LVM riserva un volume logico per i dati e un volume logico per i metadati.
L'estensione continua di piccole fette, può riempire il volume dei metadati col rischio di corrompere l'intero thin pool e prima che succeda, anche il volume dei metadati può dover essere esteso.
lvextend --poolmetadatasize +1G vg_lab/lv_tp
3. Thin Pool e snapshot
Un altro bel vantaggio della modalità thin pool è quello di facilitare l'uso delle snapshot.
Trattandosi di volumi virtuali, la dimensione della snapshot non ha bisogno di essere dichiarata. La creazione di snapshot è estremamente semplice.
# creazione di una snapshot
lvcreate -s -n lv_snap vg_lab/vol_virt
Come pure sia la creazione di snapshot annidate che il rollback risultano molto più semplici ed efficienti.
# creazione di una snapshot
lvcreate -s -n lv_snap1 vg_lab/vol_virt
# creazione di una snapshot annidata
lvcreate -s -n lv_snap2 vg_lab/lv_snap1
# rollback
umount vol_1
lvconvert --merge vg_lab/lv_snap2
mount -t ext4 -o defaults /dev/vg_lab/vol_virt vol_1
E a proposito di snapshot, occorre fare qualche osservazione.
Una serie di snapshot thin annidate, non è una catena di patch incrementali esposte al filesystem come si potrebbe pensare.
In virtù del CoW, la snapshot annidate fotograferanno sempre lo stesso istante: quello del file system all'origine.
Facciamo un esempio:
lvcreate -V 10g -T vgtest/thinpool -n vmroot
mkfs.ext4 /dev/vgtest/vmroot
mount /dev/vgtest/vmroot /mnt/test
echo ORIGINAL > /mnt/test/file.txt
umount test
lvcreate -s -n snap1 vgtest/vmroot
mount /dev/vgtest/vmroot /mnt/test
echo MOD1 > /mnt/test/file.txt
umount /mnt/test
lvcreate -s -n snap2 vgtest/snap1
mount /dev/vgtest/vmroot /mnt/test
echo MOD2 > /mnt/test/file.txt
umount /mnt/test
lvcreate -s -n snap3 vgtest/snap2
mount /dev/vgtest/vmroot /mnt/test
echo MOD3 > /mnt/test/file.txt
umount /mnt/test
In questo esempio creo un volume virtuale, vmroot, e 3 snap annidate.
- Monto il volume virtuale.
- La prima snapshot,
snap1, fotografa il file system del volume virtuale che contiene il file con “ORIGINAL”.
- Il volume virtuale viene montato e il file viene modificato.
- La seconda snapshot,
snap2, fotografa snap1 che a sua volta conteneva il file system del volume virtuale che contiene il file con “ORIGINAL”.
- Il volume virtuale viene montato e il file viene modificato.
- La terza snapshot,
snap3, fotografa snap2 che a sua volta conteneva snap1.. ecc.
Quindi snapshot siffatte non realizzano un versioning del file system come si potrebbe pensare, piuttosto possono essere utili per creare alberi di cloni/read-only, ambienti temporanei derivati da uno stato consistente, ecc.
In sostanza tornano utili quando ho una base da cui faccio derivare n snapshot che condividono i blocchi comune e con CoW minimizzo lo spazio.
Il merge di una qualunque snapshot ricondurrà il file system allo stato originario.
origin
├── snap1
├── snap2
├── snap3
Per lavorare sul delta come immaginiamo, si dovranno montare via via le snapshop, non il volume virtuale, e modificare quelle.
lvcreate -V 10g -T vgtest/thinpool -n vmroot
mkfs.ext4 /dev/vgtest/vmroot
mount /dev/vgtest/vmroot /mnt/test
echo ORIGINAL > /mnt/test/file.txt
umount /mnt/test
lvcreate -s -n snap1 vgtest/vmroot
lvchange -ay -K vgtest/snap1
mount /dev/vgtest/snap1 /mnt/test
echo MOD1 > /mnt/test/file.txt
umount /mnt/test
lvcreate -s -n snap2 vgtest/snap1
lvchange -ay -K vgtest/snap2
mount /dev/vgtest/snap2 /mnt/test
echo MOD2 > /mnt/test/file.txt
umount /mnt/test
lvcreate -s -n snap3 vgtest/snap2
lvchange -ay -K vgtest/snap3
mount /dev/vgtest/snap3 /mnt/test
echo MOD3 > /mnt/test/file.txt
umount /mnt/test
In questo modo si “inverte” la logica del merge che, prima riconduceva il file system allo stato inizale, ora invece consolida le modifiche delle snapshot
origin
└── snap1
└── snap2
└── snap3
Il merge va fatto in ordine se si vogliono acquisire correttamente i delta.
Tuttavia questo approccio
- è raro
- è difficile da gestire
- complica i merge
- può creare dependency tree intricati
Per questo quasi tutti:
- snapshot sempre dell’origin
- mai snapshot di snapshot
- rollback lineare
4. Cache Pool
Il cache pool di LVM serve a migliorare l'accesso a dispositivi tradizionalmente lenti e lo fa combinando dischi HDD con SSD/NVMe.
In sostanza avremo un gruppo di volumi costituito dai dischi HDD e un altro gruppo di volumi costituito dai dischi SDD/NVMe, la nostra cache.
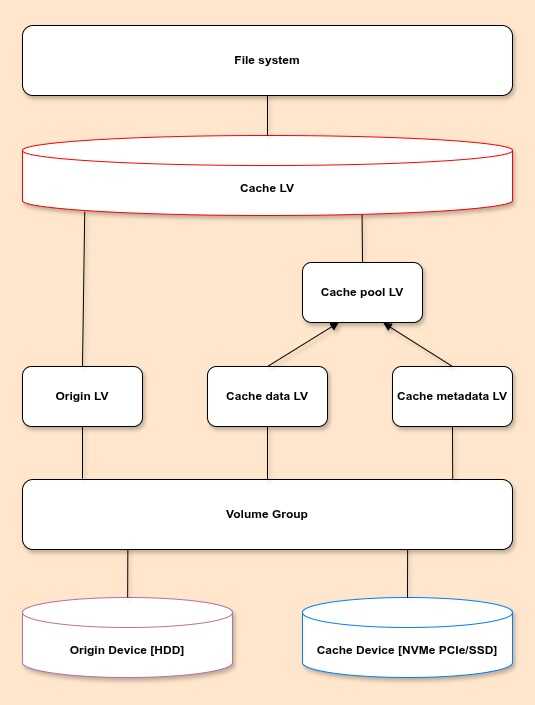
Il Logical Volume Cache sul disco veloce migliora l'accesso ad uno specifico volume logico del disco lento e prevede il ricorso a tutta una serie di tipi di volumi logici abbastanza variegata:
- Origin LV: volume logico orignale costituito dai dischi lenti
- Cache pool LV: volume logico composto a sua volta da altri due voumi logici: dati della cache e metadati della cache
- Cache data LV: volume logico contenente i blocchi di dati per il Cache pool LV.
- Cache metadata LV: volume logico contenente i metadatati per il Cache pool LV.
- Cache LV: volume logico contenente l'Origin LV e Il Cache pool LV. È il volume realemente utilizzabile
- Spare metadata LV: volume logico correlato ad una funzione di recovery data failure
Quando si crea una cache ho due possibilità a seconda che si voglia massimizzare velocità o affidabilità:
- writethrough: Le operazioni di scrittura vengono inviate sia alla cache SSD che all'Origin HDD. La lettura avviene preferibilmente dalla cache.
È la modalità più sicura. Se l'SSD muore, nessun dato va perso ma è meno efficiente in scrittura perché Origin HDD diventa il collo di bottiglia,
- writeback: più veloce ma meno sicuro. Le scritture vengono salvate immediatamente sulla cache veloce e sincronizzate sull'HDD in background in un secondo momento. Se si dovesse rompere il disco di cache, c'è il rischio di una perdita di dati.
Il dimensionamento della cache è proporzionale alla dimensione del disco origin.
Di solito si aggira in un range del 2-10%
- 2%: archiviazione sequenziale, file di grandi dimensioni;
- 5%: standard consigliato. File server generico, utilizzo desktop/workstation;
- 10%: carichi di lavoro intensivi e casuali come database SQL/NoSQL attivi, nodi di virtualizzazione densi (molte VM), ecc.
Non è necessario prevedere da subito Il disco di cache (se c'è stata la possibilità tanto meglio), ma si può aggiungere in un secondo momento estendendo il gruppo di volumi contenente l'HDD e battezzando l'LV di cache.
Perpariamo il nostro laboratorio in cui abbiamo un HD lento con un unico volume logico a cui applichiamo una cache.
- disco lento: 2 GiB
- disco veloce: 500 MiB
- cache: 5% di 2 GiB (~100 MiB)
# creazione del device fisico per il laboratorio
fallocate -l 2GiB slow_disk.img
# attach del device e creazione del gruppo di volumi
vgcreate vg_lab $(losetup -Pf --show slow_disk.img)
# creazione e formattazione dell'unico volume logico
lvcreate -n lv_origin vg_lab -l 100%FREE
mkfs.ext4 /dev/vg_lab/lv_origin
Ora aggiungiamo il disco che farà da cache estendendo il gruppo di volumi:
# creazione del device fisico di cache per il laboratorio
fallocate -l 500MiB fast_disk.img
# attach del dispositivo e estensione del gruppo di volumi
DEV_FAST=$(losetup -Pf --show fast_disk.img)
vgextend vg_lab "${DEV_FAST}"
Il cache pool lv può essere configurato automaticamente oppure manualente.
4.1. Caso 1: configurazione automatica del cache pool lv
In un unico passaggio, convertiamo il volume logico attuale in un volume logico con cache.
lvcreate \
--type cache \
--cachemode writethrough \
-l 5%FREE \
-n cache_pool vg_lab/lv_origin "${DEV_FAST}"
Dopo questo comando vedremo che il volume logico lv_origin incapsula il cache pool (lv_origincache_cpool) e il volume logico dei dati (lv_origin_corig).
Il cache pool è composto da due volumi logici per i dati (lv_origincache_cpool_cdata) e i metadati (lv_origincache_cpool_cmeta).
Infine distinguiamo anche il volume logico di metadati spare da utilizzare per un eventuale data recovery failure (lvol0_pmspare).
lvs -a
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
home vg_fedora -wi-ao---- 409,81g
root vg_fedora -wi-ao---- 50,00g
swap vg_fedora -wi-ao---- 16,00g
lv_origin vg_lab Cwi-a-C--- <2,00g [lv_origincache_cpool] [lv_origin_corig] 0,00 0,59 0,00
[lv_origin_corig] vg_lab owi-aoC--- <2,00g
[lv_origincache_cpool] vg_lab Cwi---C--- 8,00m 0,00 0,59 0,00
[lv_origincache_cpool_cdata] vg_lab Cwi-ao---- 8,00m
[lv_origincache_cpool_cmeta] vg_lab ewi-ao---- 8,00m
[lvol0_pmspare] vg_lab ewi------- 8,00m
4.2. Caso 2: configurazione manuale del cache pool lv
Se invece vogliamo intervenire su ogni singolo passaggio della creazione del cache pool:
# creazione dei volumi logici meta e dati per il cache pool
lvcreate -n cache_pool_meta -L 10M vg_lab "${DEV_FAST}"
lvcreate -n cache_pool -l 5%FREE vg_lab "${DEV_FAST}"
# creazione del cache pool assemblando meta e data
lvconvert \
--type cache-pool \
--cachemode writethrough \
--poolmetadata vg_lab/cache_pool_meta vg_lab/cache_pool
# conversione del volume logico origin nel nuovo volume logico con cache
lvconvert \
--type cache \
--cachepool vg_lab/cache_pool vg_lab/lv_origin
In realtà è meglio lasciare a LVM il compito di dimensionare correttamente il volume per i metadati.
# creazione della cache pool
lvcreate --type cache-pool -l 5%FREE -n cache_cpool vg_lab "${DEV_FAST}"
# conversione del volume logico originale in un volume logico con cache
lvconvert \
--type cache \
--cachepool vg_lab/cache_cpool vg_lab/lv_origin
4.3. Switch della modalità
Per cambiare modalità fra writetrough e writeback (se non specificato nella definizione della cache pool, il default è writethrough).
lvchange --cachemode writeback vg_lab/lv_origin
4.4. Rimozione della cache
Se volessi levare il disco di cache e ritornare al volume logico di partenza:
lvconvert --uncache vg_lab/lv_origin
Logical volume "lv_origincache_cpool" successfully removed.
Logical volume vg_lab/lv_origin is not cached.
```https://noblogo.org/ebdpsbxxid/edit#publish
e `lvs -a` mostra il volume logico in queste condizioni:
```bash
lvs -a
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
lv_origin vg_lab -wi-a----- <2,00g
4.5. Monitoraggio
lvs -a -o lv_name,lv_size,cache_mode,data_percent,metadata_percent vg_lab
5. LVM Stripe
Analogo a Raid 0, l'uso diretto di stripe in lvm attraverso il mappatore interno dm-stripe, permette di definire su quali e quanti dischi va frammentata l'informazione da memorizzare allo scopo di aumentare le prestazioni.
Considerazioni:
- Il gruppo di volumi deve contenere almeno due dischi fisici.
- È preferibile che i dischi fisici abbiano tutti la stessa velocità altrimenti quello più lento diventerà il collo di bottiglia.
- È possibile che i < n, dove i è il numero di dischi per lo stripe e n è il numero totale di dischi del gruppo di volumi
- È anche possibile specificare i dischi va applicato lo stripe.
- La dimensione dello stripe è di 64K come default. Ma per file molto grandi, video o database, la dimensione può essere anche di 128K o 256K
# creazione di un gruppo di volumi con 3 dischi
vgcreate vg_lab /dev/sdb /dev/sdc /dev/sdd
# stripe su due dischi a caso di vg_lab
lvcreate -i 2 -I 64k -L 10G -n lv_stripe vg_lab
# stripe su tutti i dischi di vg_lab
lvcreate -i 3 -I 64k -L 10G -n lv_stripe vg_lab
# stripe sui dischi sdc e sdd con uno stripe size di 128K
lvcreate -i 2 -I 128k -L 10G -n lv_stripe vg_lab /dev/sdc /dev/sdd
Come ogni raid 0, massime prestazioni e sicurezza 0. Se un disco si rompe, addio ai dati.
6. LVM Mirror
Come per lvm stripe analogo a raid 0, il mirror in lvm tramite il mappatore interno dm-mirror, è assimiliabile a raid 1.
Come ogni raid 1 che si rispetti, il chiaro vantaggio di questo approccio è proprio la ridondanza dei dati che, al costo del sacrificio di un disco, permette di correre ai ripari se uno dei dischi si danneggia.
# creazione di un gruppo di volumi con 2 dischi
vgcreate vg_lab /dev/sdb /dev/sdc
# creazione del volume logico "mirror"
lvcreate -m 1 -L 10G -n lv_mirror vg_lab
Il mirror diretto attraverso LVM in realtà è considerato legacy. Si consiglia di usare l'approccio più moderno che prevede di specificare il tipo, raid x, nell'invocazione di lvcreate perché userà il modulo specializzato del kernel per il raid software.
LVM mirror infatti pur essendo funzionalmente equivalente ad un raid 1 non è altrettanto efficace perché si basa su un log di sincronizzazione dove lvm tiene traccia degli elementi allineati.
Tale log deve stare su un altro disco (che diventa un altro punto di vulnerabilità) e quando c'è bisogno di ricostruire l'array in caso di rottura di un disco, l'operazione è molto lenta.
7. LVM Raid
Il raid lvm è un modo per prendere il meglio dei due mondi.
Non è che LVM abbia una sua implementazione del raid.
Il raid “tradizionale” si basa sul sottosistema Multiple Devices del kernel e lavora direttamente sui dispositivi a blocchi.
LVM si interfaccia direttamente con il modulo md del kernel per attingere alle funzioni di raid così da offrire, attraverso device mapper, un'interfaccia unica per la gestione dei volumi e del raid.
7.1. Raid 0 (Stripe)
lvcreate --type raid0 -i 2 -I 64k -L 10G -n lv_raid0 vg_lab
A differenza del mirror, non ci sono gli stessi problemi per stripe. Il mappatore nativo di LVM, dm-stripe, fa bene il suo lavoro.
Usare lvmraid in questo caso resta vantaggioso per ragioni di coerenza. L'uso del modulo md rende possibile un'eventuale evoluzione verso livelli superiori (come RAID 1 o RAID 5).
7.2. Raid 1 (Mirroring)
L'alternativa moderna al vecchio lvm mirror che risolve i suoi problemi di efficienza usando il modulo md.
Basandoci sull'esempio di prima:
lvcreate --type raid1 -m 1 -L 10G -n lv_raid1 vg_lab
7.3. Raid 5 (Stripe con parità singola)
Creiamo un volume logico con RAID 5 basato su 4 dischi (stripe su 3 dischi e uno per la parità):
# creazione di un gruppo di volumi con 4 dischi
vgcreate vg_lab /dev/sdb /dev/sdc /dev/sdd /dev/sde
# creazione del volume logico con RAID 5
lvcreate --type raid5 -i 3 -L 10G -n lv_raid5 vg_lab
7.4. Raid 6 (Stripe con parità doppia)
Se vogliamo una parità doppia su 4 dischi (2 stripe e due di parità);
# creazione di un gruppo di volumi con 4 dischi
vgcreate vg_lab /dev/sdb /dev/sdc /dev/sdd /dev/sde
# creazione del volume logico con RAID 5
lvcreate --type raid6 -i 2 -L 10G -n lv_raid6 vg_lab
7.5. Raid 10
E veniamo al RAID 1+0, uno stripe su n array in mirror per combinare l'efficienza dello stripe con la sicurezza del mirror:
# creazione di un gruppo di volumi con 4 dischi
vgcreate vg_lab /dev/sdb /dev/sdc /dev/sdd /dev/sde
# creazione del volume logico con RAID 5
lvcreate --type raid10 -i 2 -m 1 -L 10G -n lv_raid10 vg_lab
7.6. Come monitorare il raid
Metodo rapido:
lvs -o name,vg_name,copy_percent,lv_attr,raid_health_status,devices vg_lab
# Combinandolo con watch posso vedere per es. la percentuale
# di completamento della copia in caso di sostituzione del disco
watch -n 1 lvs -o name,vg_name,copy_percent,lv_attr,raid_health_status,devices vg_lab
Metodo dettagliato:
lvdisplay vg_lab/lv_raid5
Monitoraggio a basso livello:
Balamente, visto che viene usato il modulo md:
cat /proc/mdstat
7.7. Come intervenire in caso di guasto
Con lvs vedremo che lo stato del volume è diventato degraded.
Con pvpdisplay possiamo individuare il device danneggiato che comparirà come unknown device o con un sacco di errori I/O .
Dopo aver estratto il disco e messo quello nuovo, supponendo sia /dev/sdc, procediamo con la ricostruzione dell'array:
# inizializzazione nuovo disco
pvcreate /dev/sdc
# aggiunta del nuovo disco al gruppo
vgextend vg_lab /dev/sdc
# array rebuild
lvconvert --repair vg_lab/lv_raid5
# rimozione disco danneggiato dal gruppo di volumi
vgreduce --removemissing vg_lab
#lvm #dm #devicemapper #md #multipledevices #snapshot #thinpool #thinprovisioning #cachepool #raid #lvmraid
 Al di là della storia, quello che mi ha colpito, però, è il concetto di mondi effluenti introdotto dall'autrice.
Secondo Laurence Arne-Sayles, il mad scientist o mad wizard del romanzo, un mondo effluente viene generato dalle energie creative e magiche che, costrette ad abbandonare un mondo devono sfogare da qualce parte e perciò ne creano uno nuovo.
L'idea di Arne-Sayles è che nell'antichità gli esseri umani avessero grandi poteri, fossero plamatori di forme [^cosa curiosa]. Potevano trasformarsi, volare, comandare il mare; potevano farsi trasportare dai fiumi parlare con loro, ottenendo risposta [^altra cosa curiosa].
Poi, con il progresso, queste abilità animistiche, la forza creatrice, la capacità di plasmare le forme sono andate perse. Solo che l'energia non si può distruggere e quindi tutta quella che gli umani hanno smesso di usare non sfruttando le loro capacità ha dovuto sfogarsi in qualche modo, andare da un'altra parte. Come l'acqua che filtra in un pertugio nel terreno e lentamente scava una caverna, così l'energia è filtrata in un pertugio tra i mondi e ha creato un mondo nuovo, una sorta di dimensione parallela ch eporta con sé il ricordo dal mondo da cui proviene.
Al di là della storia, quello che mi ha colpito, però, è il concetto di mondi effluenti introdotto dall'autrice.
Secondo Laurence Arne-Sayles, il mad scientist o mad wizard del romanzo, un mondo effluente viene generato dalle energie creative e magiche che, costrette ad abbandonare un mondo devono sfogare da qualce parte e perciò ne creano uno nuovo.
L'idea di Arne-Sayles è che nell'antichità gli esseri umani avessero grandi poteri, fossero plamatori di forme [^cosa curiosa]. Potevano trasformarsi, volare, comandare il mare; potevano farsi trasportare dai fiumi parlare con loro, ottenendo risposta [^altra cosa curiosa].
Poi, con il progresso, queste abilità animistiche, la forza creatrice, la capacità di plasmare le forme sono andate perse. Solo che l'energia non si può distruggere e quindi tutta quella che gli umani hanno smesso di usare non sfruttando le loro capacità ha dovuto sfogarsi in qualche modo, andare da un'altra parte. Come l'acqua che filtra in un pertugio nel terreno e lentamente scava una caverna, così l'energia è filtrata in un pertugio tra i mondi e ha creato un mondo nuovo, una sorta di dimensione parallela ch eporta con sé il ricordo dal mondo da cui proviene.
 Non ho fatto foto del sacchetto quindi l'ho generato con l'AI, perdonatemi
Non ho fatto foto del sacchetto quindi l'ho generato con l'AI, perdonatemi